HTTP 最早被用来做浏览器与服务器之间交互 HTML 和表单的通讯协议;后来又被被广泛的扩充到接口格式的定义上。所以在讨论 GET 和 POST 区别的时候,需要现确定下到底是浏览器使用的 GET/POST 还是用 HTTP 作为接口传输协议的场景。
浏览器的 GET 和 POST
这里特指浏览器中非Ajax 的 HTTP 请求,即从 HTML 和浏览器诞生就一直使用的 HTTP 协议中的 GET/POST。浏览器用 GET 请求来获取一个 html 页面/图片/css/js 等资源;用 POST 来提交一个<form>表单,并得到一个结果的网页。
浏览器将 GET 和 POST 定义为:
GET:
“读取“一个资源。比如 Get 到一个 html 文件。反复读取不应该对访问的数据有副作用。比如”GET 一下,用户就下单了,返回订单已受理“,这是不可接受的。没有副作用被称为“幂等“(Idempotent)。因为 GET 因为是读取,就可以对 GET 请求的数据做缓存。这个缓存可以做到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如 nginx),或者做到 server 端(用 Etag,至少可以减少带宽消耗)
POST:
在页面里<form> 标签会定义一个表单。点击其中的 submit 元素会发出一个 POST 请求让服务器做一件事。这件事往往是有副作用的,不幂等的。不幂等也就意味着不能随意多次执行。因此也就不能缓存。比如通过 POST 下一个单,服务器创建了新的订单,然后返回订单成功的界面。这个页面不能被缓存。试想一下,如果 POST 请求被浏览器缓存了,那么下单请求就可以不向服务器发请求,而直接返回本地缓存的“下单成功界面”,却又没有真的在服务器下单。那是一件多么滑稽的事情。因为 POST 可能有副作用,所以浏览器实现为不能把 POST 请求保存为书签。想想,如果点一下书签就下一个单,是不是很恐怖?。此外如果尝试重新执行 POST 请求,浏览器也会弹一个框提示下这个刷新可能会有副作用,询问要不要继续。
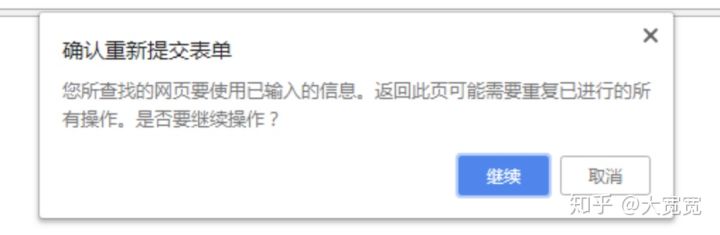
当然,服务器的开发者完全可以把 GET 实现为有副作用;把 POST 实现为没有副作用。只不过这和浏览器的预期不符。把 GET 实现为有副作用是个很可怕的事情。 我依稀记得很久之前百度贴吧有一个因为使用 GET 请求可以修改管理员的权限而造成的安全漏洞。反过来,把没有副作用的请求用 POST 实现,浏览器该弹框还是会弹框,对用户体验好处改善不大。
但是后边可以看到,将 HTTP POST 作为接口的形式使用时,就没有这种弹框了。于是把一个 POST 请求实现为幂等就有实际的意义。POST 幂等能让很多业务的前后端交互更顺畅,以及避免一些因为前端 bug,触控失误等带来的重复提交。将一个有副作用的操作实现为幂等必须得从业务上能定义出怎么就算是“重复”。如提交数据中增加一个 dedupKey 在一个交易会话中有效,或者利用提交的数据里可以天然当 dedupKey 的字段。这样万一用户强行重复提交,服务器端可以做一次防护。
GET 和 POST 携带数据的格式也有区别。当浏览器发出一个 GET 请求时,就意味着要么是用户自己在浏览器的地址栏输入,要不就是点击了 html 里 a 标签的 href 中的 url。所以其实并不是 GET 只能用 url,而是浏览器直接发出的 GET 只能由一个 url 触发。所以没办法,GET 上要在 url 之外带一些参数就只能依靠 url 上附带 querystring。但是 HTTP 协议本身并没有这个限制。
浏览器的 POST 请求都来自表单提交。每次提交,表单的数据被浏览器用编码到 HTTP 请求的 body 里。浏览器发出的 POST 请求的 body 主要有有两种格式,一种是 application/x-www-form-urlencoded 用来传输简单的数据,大概就是”key1=value1&key2=value2”这样的格式。另外一种是传文件,会采用 multipart/form-data 格式。采用后者是因为 application/x-www-form-urlencoded 的编码方式对于文件这种二进制的数据非常低效。
浏览器在 POST 一个表单时,url 上也可以带参数,只要<form action="url" >里的 url 带 querystring 就行。只不过表单里面的那些用<input>等标签经过用户操作产生的数据都在会在 body 里。
因此我们一般会泛泛的说“GET 请求没有 body,只有 url,请求数据放在 url 的 querystring 中;POST 请求的数据在 body 中“。但这种情况仅限于浏览器发请求的场景。
接口中的 GET 和 POST
这里是指通过浏览器的 Ajax api,或者 iOS/Android 的 App 的 http client,java 的 commons-httpclient/okhttp 或者是 curl,postman 之类的工具发出来的 GET 和 POST 请求。此时 GET/POST 不光能用在前端和后端的交互中,还能用在后端各个子服务的调用中(即当一种 RPC 协议使用)。尽管 RPC 有很多协议,比如 thrift,grpc,但是 http 本身已经有大量的现成的支持工具可以使用,并且对人类很友好,容易 debug。HTTP 协议在微服务中的使用是相当普遍的。
当用 HTTP 实现接口发送请求时,就没有浏览器中那么多限制了,只要是符合 HTTP 格式的就可以发。HTTP 请求的格式,大概是这样的一个字符串(为了美观,我在\r\n 后都换行一下):
1 | <METHOD> <URL> HTTP/1.1\r\n |
其中的“<METHOD>“可以是 GET 也可以是 POST,或者其他的 HTTP Method,如 PUT、DELETE、OPTION……。从协议本身看,并没有什么限制说 GET 一定不能没有 body,POST 就一定不能把参放到<URL>的 querystring 上。因此其实可以更加自由的去利用格式。比如 Elastic Search 的_search api 就用了带 body 的 GET;也可以自己开发接口让 POST 一半的参数放在 url 的 querystring 里,另外一半放 body 里;你甚至还可以让所有的参数都放 Header 里——可以做各种各样的定制,只要请求的客户端和服务器端能够约定好。
当然,太自由也带来了另一种麻烦,开发人员不得不每次讨论确定参数是放 url 的 path 里,querystring 里,body 里,header 里这种问题,太低效了。于是就有了一些列接口规范/风格。其中名气最大的当属 REST。REST 充分运用 GET、POST、PUT 和 DELETE,约定了这 4 个接口分别获取、创建、替换和删除“资源”,REST 最佳实践还推荐在请求体使用 json 格式。这样仅仅通过看 HTTP 的 method 就可以明白接口是什么意思,并且解析格式也得到了统一。
json 相对于 x-www-form-urlencoded 的优势在于 1)可以有嵌套结构;以及 2)可以支持更丰富的数据类型。通过一些框架,json 可以直接被服务器代码映射为业务实体。用起来十分方便。但是如果是写一个接口支持上传文件,那么还是 multipart/form-data 格式更合适。
REST 中 GET 和 POST 不是随便用的。在 REST 中, 【GET】 + 【资源定位符】被专用于获取资源或者资源列表,比如:
1 | GET http://foo.com/books 获取书籍列表 |
与浏览器的场景类似,REST GET 也不应该有副作用,于是可以被反复无脑调用。浏览器(包括浏览器的 Ajax 请求)对于这种 GET 也可以实现缓存(如果服务器端提示了明确需要 Caching);但是如果用非浏览器,有没有缓存完全看客户端的实现了。当然,也可以从整个 App 角度,也可以完全绕开浏览器的缓存机制,实现一套业务定制的缓存框架。
REST 【POST】+ 【资源定位符】则用于“创建一个资源”,比如:
1 | POST http://foo.com/books |
这里你就能留意到浏览器中用来实现表单提交的 POST,和 REST 里实现创建资源的 POST语义上的不同。
顺便讲下 REST POST 和 REST PUT 的区别。有些 api 是使用 PUT 作为创建资源的 Method。PUT 与 POST 的区别在于,PUT 的实际语义是“replace”replace。REST 规范里提到 PUT 的请求体应该是完整的资源,包括 id 在内。比如上面的创建一本书的 api 也可以定义为:
1 | PUT http://foo.com/books |
服务器应该先根据请求提供的 id 进行查找,如果存在一个对应 id 的元素,就用请求中的数据整体替换已经存在的资源;如果没有,就用“把这个 id 对应的资源从【空】替换为【请求数据】“。直观看起来就是“创建”了。
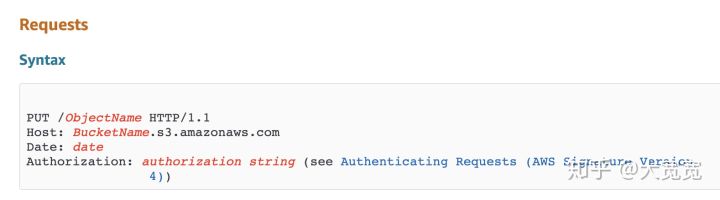
与 PUT 相比,POST 更像是一个“factory”,通过一组必要的数据创建出完整的资源。至于到底用 PUT 还是 POST 创建资源,完全要看是不是提前可以知道资源所有的数据(尤其是 id),以及是不是完整替换。比如对于 AWS S3 这样的对象存储服务,当想上传一个新资源时,其 id 就是“ObjectName”可以提前知道;同时这个 api 也总是完整的 replace 整个资源。这时的 api 用 PUT 的语义更合适;而对于那些 id 是服务器端自动生成的场景,POST 更合适一些。
有点跑题,就此打住。
回到接口这个主题,上面仅仅粗略介绍了 REST 的情况。但是现实中总是有 REST 的变体,也可能用非 REST 的协议(比如 JSON-RPC、SOAP 等),每种情况中的 GET 和 POST 又会有所不同。
关于安全性
我们常听到 GET 不如 POST 安全,因为 POST 用 body 传输数据,而 GET 用 url 传输,更加容易看到。但是从攻击的角度,无论是 GET 还是 POST 都不够安全,因为 HTTP 本身是明文协议。每个 HTTP 请求和返回的每个 byte 都会在网络上传播,不管是 url,header 还是 body。这完全不是一个“是否容易在浏览器地址栏上看到“的问题。
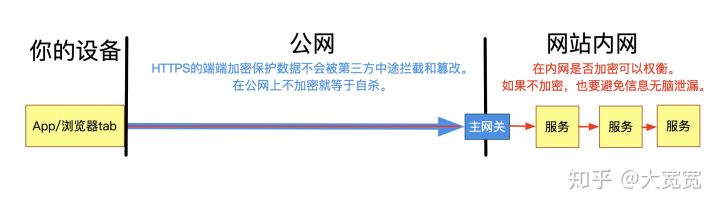
为了避免传输中数据被窃取,必须做从客户端到服务器的端端加密。业界的通行做法就是 https——即用 SSL 协议协商出的密钥加密明文的 http 数据。这个加密的协议和 HTTP 协议本身相互独立。如果是利用 HTTP 开发公网的站点/App,要保证安全,https 是最最基本的要求。
当然,端端加密并不一定非得用 https。比如国内金融领域都会用私有网络,也有 GB 的加密协议 SM 系列。但除了军队,金融等特殊机构之外,似乎并没有必要自己发明一套类似于 ssl 的协议。
回到 HTTP 本身,的确 GET 请求的参数更倾向于放在 url 上,因此有更多机会被泄漏。比如携带私密信息的 url 会展示在地址栏上,还可以分享给第三方,就非常不安全了。此外,从客户端到服务器端,有大量的中间节点,包括网关,代理等。他们的 access log 通常会输出完整的 url,比如 nginx 的默认 access log 就是如此。如果 url 上携带敏感数据,就会被记录下来。但请注意,就算私密数据在 body 里,也是可以被记录下来的,因此如果请求要经过不信任的公网,避免泄密的唯一手段就是 https。这里说的“避免 access log 泄漏“仅仅是指避免可信区域中的 http 代理的默认行为带来的安全隐患。比如你是不太希望让自己公司的运维同学从公司主网关的 log 里看到用户的密码吧。
另外,上面讲过,如果是用作接口,GET 实际上也可以带 body,POST 也可以在 url 上携带数据。所以实际上到底怎么传输私密数据,要看具体场景具体分析。当然,绝大多数场景,用 POST + body 里写私密数据是合理的选择。一个典型的例子就是“登录”:
1 | POST http://foo.com/user/login |
安全是一个巨大的主题,有由很多细节组成的一个完备体系,比如返回私密数据的 mask,XSS,CSRF,跨域安全,前端加密,钓鱼,salt,…… POST 和 GET 在安全这件事上仅仅是个小角色。因此单独讨论 POST 和 GET 本身哪个更安全意义并不是太大。只要记得一般情况下,私密数据传输用 POST + body 就好。
关于编码
常见的说法有,比如 GET 的参数只能支持 ASCII,而 POST 能支持任意 binary,包括中文。但其实从上面可以看到,GET 和 POST 实际上都能用 url 和 body。因此所谓编码确切地说应该是 http 中 url 用什么编码,body 用什么编码。
先说下 url。url 只能支持 ASCII 的说法源自于RFC1738
Thus, only alphanumerics, the special characters “$-_.+!*‘(),”, and reserved characters used for their reserved purposes may be used unencoded within a URL.
实际上这里规定的仅仅是一个 ASCII 的子集[a-zA-Z0-9$-_.+!*’(),]。它们是可以“不经编码”在 url 中使用。比如尽管空格也是 ASCII 字符,但是不能直接用在 url 里。
那这个“编码”是什么呢?如果有了特殊符号和中文怎么办呢?这里要介绍一种叫做 percent encoding 的方法,这也就是为啥我们偶尔看到 url 里有一坨%和 16 位数字组成的序列。
使用 Percent Encoding,即使是binary data,也是可以通过编码后放在 URL 上的。

但要特别注意,这个编码方式只管把字符转换成 URL 可用字符,但是却不管字符集编码(比如中文到底是用 UTF8 还是 GBK)这块早期一直都相当乱,也没有什么统一规范。比如有时跟网页编码一样,有的是操作系统的编码一样。最要命的是浏览器的地址栏是不受开发者控制的这样,对于同样一个带中文的 url,如果有的浏览器一定要用 GBK(比如老的 IE8),有的一定要用 UTF8(比如 chrome)。后端就可能认不出来。对此常用的办法是避免让用户输入这种带中文的 url。如果有这种形式的请求,都改成用户界面上输入,然后通过 Ajax 发出的办法。Ajax 发出的编码形式开发者是可以 100%控制的。
不过目前基本上 utf8 已经大一统了。现在的开发者除非是被国家规定要求一定要用 GB 系列编码的场景,基本上不会再遇到这类问题了。
关于 url 的编码,阮一峰的一篇文章有比较详细的解释.
顺便说一句,尽管在浏览器地址栏可以看到中文。但这种 url 在发送请求过程中,浏览器会把中文用字符编码+Percent Encode 翻译为真正的 url,再发给服务器。浏览器地址栏里的中文只是想让用户体验好些而已。
再讨论下 Body。HTTP Body 相对好些,因为有个 Content-Type 来比较明确的定义。比如:
1 | POST xxxxxx HTTP/1.1 |
这里 Content-Type 会同时定义请求 body 的格式(application/x-www-form-urlencoded)和字符编码(UTF-8)。
所以 body 和 url 都可以提交中文数据给后端,但是 POST 的规范好一些,相对不容易出错,容易让开发者安心。对于 GET+url 的情况,只要不涉及到在老旧浏览器的地址栏输入 url,也不会有什么太大的问题。
回到 POST,浏览器直接发出的 POST 请求就是表单提交,而表单提交只有 application/x-www-form-urlencoded 针对简单的 key-value 场景;和 multipart/form-data,针对只有文件提交,或者同时有文件和 key-value 的混合提交表单的场景。
如果是 Ajax 或者其他 HTTP Client 发出去的 POST 请求,其 body 格式就非常自由了,常用的有 json,xml,文本,csv……甚至是你自己发明的格式。只要前后端能约定好即可。
浏览器的 POST 需要发两个请求吗
上文中的”HTTP 格式“清楚的显示了 HTTP 请求可以被大致分为“请求头”和“请求体”两个部分。使用 HTTP 时大家会有一个约定,即所有的“控制类”信息应该放在请求头中,具体的数据放在请求体里“。于是服务器端在解析时,总是会先完全解析全部的请求头部。这样,服务器端总是希望能够了解请求的控制信息后,就能决定这个请求怎么进一步处理,是拒绝,还是根据 content-type 去调用相应的解析器处理数据,或者直接用 zero copy 转发。
比如在用 Java 写服务时,请求处理代码总是能从 HttpSerlvetRequest 里 getParameter/Header/url。这些信息都是请求头里的,框架直接就解析了。而对于请求体,只提供了一个 inputstream,如果开发人员觉得应该进一步处理,就自己去读取和解析请求体。这就能体现出服务器端对请求头和请求体的不同处理方式。
举个实际的例子,比如写一个上传文件的服务,请求 url 中包含了文件名称,请求体中是个尺寸为几百兆的压缩二进制流。服务器端接收到请求后,就可以先拿到请求头部,查看用户是不是有权限上传,文件名是不是符合规范等。如果不符合,就不再处理请求体的数据了,直接丢弃。而不用等到整个请求都处理完了再拒绝。
为了进一步优化,客户端可以利用 HTTP 的 Continued 协议来这样做:客户端总是先发送所有请求头给服务器,让服务器校验。如果通过了,服务器回复“100 - Continue”,客户端再把剩下的数据发给服务器。如果请求被拒了,服务器就回复个 400 之类的错误,这个交互就终止了。这样,就可以避免浪费带宽传请求体。但是代价就是会多一次 Round Trip。如果刚好请求体的数据也不多,那么一次性全部发给服务器可能反而更好。
基于此,客户端就能做一些优化,比如内部设定一次 POST 的数据超过 1KB 就先只发“请求头”,否则就一次性全发。客户端甚至还可以做一些 Adaptive 的策略,统计发送成功率,如果成功率很高,就总是全部发等等。不同浏览器,不同的客户端(curl,postman)可以有各自的不同的方案。不管怎样做,优化目的总是在提高数据吞吐和降低带宽浪费上做一个折衷。
因此到底是发一次还是发 N 次,客户端可以很灵活的决定。因为不管怎么发都是符合 HTTP 协议的,因此我们应该视为这种优化是一种实现细节,而不用扯到 GET 和 POST 本身的区别上。更不要当个什么世纪大发现。
到底什么算请求体
看完了上面的内容后,读者也许会对“什么是请求体”感到困惑不已,比如 x-www-form-endocded 编码的 body 算不算“请求体”呢?
从 HTTP 协议的角度,“请求头”就是 Method + URL(含 querystring)+ Headers;再后边的都是请求体。
但是从业务角度,如果你把一次请求立即为一个调用的话。比如上面的
1 | POST http://foo.com/books |
用 Java 写大概等价于
1 | createBook("大宽宽的碎碎念", "大宽宽"); |
那么这一行函数名和两个参数都可以看作是一个请求,不区分头和体。即便用 HTTP 协议实现,title 和 author 编码到了 HTTP 请求体中。Java 的 HttpServletRequest 支持用 getParameter 方法获取 x-www-url-form-encoded 中的数据,表达的意思就是“请求“的”参数“。
对于 HTTP,需要区分【头】和【体】,Http Request 和 Http Response 都这么区分。Http 这么干主要用作:
- 对于 HTTP 代理
- 支持转发规则,比如 nginx 先要解析请求头,拿到 URL 和 Header 才能决定怎么做(转发 proxy_pass,重定向 redirect,rewrite 后重新判断……)
- 需要用请求头的信息记录 log。尽管请求体里的数据也可以记录,但一般只记录请求头的部分数据。
- 如果代理规则不涉及到请求体,那么请求体就可以不用从内核态的 page cache 复制一份到用户态了,可以直接 zero copy 转发。这对于上传文件的场景极为有效。
- ……
- 对于 HTTP 服务器
- 可以通过请求头进行 ACL 控制,比如看看 Athorization 头里的数据是否能让认证通过
- 可以做一些拦截,比如看到 Content-Length 里的数太大,或者 Content-Type 自己不支持,或者 Accept 要求的格式自己无法处理,就直接返回失败了。
- 如果 body 的数据很大,利用 Stream API,可以方便支持一块一块的处理数据,而不是一次性全部读取出来再操作,以至于占用大量内存。
- ……
但从高一级的业务角度,我们在意的其实是【请求】和【返回】。当我们在说“请求头”这三个字时,也许实际的意思是【请求】。而用 HTTP 实现【请求】时,可能仅仅用到【HTTP 的请求头】(比如大部分 GET 请求),也可能是【HTTP 请求头】+【HTTP 请求体】(比如用 POST 实现一次下单)。
总之,这里有两层,不要混哦。
关于 URL 的长度
因为上面提到了不论是 GET 和 POST 都可以使用 URL 传递数据,所以我们常说的“GET 数据有长度限制“其实是指”URL 的长度限制“。
HTTP 协议本身对 URL 长度并没有做任何规定。实际的限制是由客户端/浏览器以及服务器端决定的。
先说浏览器。不同浏览器不太一样。比如我们常说的 2048 个字符的限制,其实是 IE8 的限制。并且原始文档的说的其实是“URL 的最大长度是 2083 个字符,path 的部分最长是 2048 个字符“。见链接。IE8 之后的 IE URL 限制我没有查到明确的文档,但有些资料称 IE 11 的地址栏只能输入法 2047 个字符,但是允许用户点击 html 里的超长 URL。我没实验,哪位有兴趣可以试试。

Chrome 的 URL 限制是 2MB,见链接

Safari,Firefox 等浏览器也有自己的限制,但都比 IE 大的多,这里就不挨个列出了。
然而新的 IE 已经开始使用 Chrome 的内核了,也就意味着“浏览器端 URL 的长度限制为 2048 字符”这种说法会慢慢成为历史。
其他的客户端,比如 Java 的,js 的 http client 大多数也并没有限制 URL 最大有多长。
除了浏览器,服务器这边也有限制,比如 apache 的 LimieRequestLine 指令。

apache 实际上限制的是 HTTP 请求第一行“Request Line“的长度,即<METHOD><URL><VERSION>那一行。
再比如 niginx 用 large_client_header_buffers 指令来分配请求头中的很长数据的 buffer。这个 buffer 可以用来处理 url,header value 等。

Tomcat 的限制是 web.xml 里 maxHttpHeaderSize 来设置的,控制的是整个“请求头”的总长度。

为啥要限制呢?如果写过解析一段字符串的代码就能明白,解析的时候要分配内存。对于一个字节流的解析,必须分配 buffer 来保存所有要存储的数据。而 URL 这种东西必须当作一个整体看待,无法一块一块处理,于是就处理一个请求时必须分配一整块足够大的内存。如果 URL 太长,而并发又很高,就容易挤爆服务器的内存;同时,超长 URL 的好处并不多,我也只有处理老系统的 URL 时因为不敢碰原来的逻辑,又得追加更多数据,才会使用超长 URL。
对于开发者来说,使用超长的 URL 完全是给自己埋坑,需要同时要考虑前后端,以及中间代理每一个环节的配置。此外,超长 URL 会影响搜索引擎的爬虫,有些爬虫甚至无法处理超过 2000 个字节的 URL。这也就意味着这些 URL 无法被搜到,坑爹啊。
其实并没有太大必要弄清楚精确的 URL 最大长度限制。我个人的经验是,只要某个要开发的资源/api 的 URL 长度有可能达到 2000 个 bytes 以上,就必须使用 body 来传输数据,除非有特殊情况。至于到底是 GET + body 还是 POST + body 可以看情况决定。
留意,1 个汉字字符经过 UTF8 编码 + percent encoding 后会变成 9 个字节,别算错哦。
总结
上面讲了一大堆,是希望读者不要死记硬背 GET 和 POST 的区别,而是能从更广的层面去看待和思考这个问题。
最后,协议都是人定的。只要客户端和服务器能彼此认同,就能工作。在常规的情况下,用符合规范的方式去实现系统可以减少很多工作量——大家都约定好了,就不要折腾了。但是,总会有一些情况用常规规范不合适,不满足需求。这时思路也不能被规范限制死,更不要死抠 RFC。这些规范也许不能处理你遇到的特殊问题。比如:
- Elastic Search 的_search 接口使用 GET,却用 body 来表达查询,因为查询很复杂,用 querystring 很麻烦,必须用 json 格式才舒服,在请求体用 json 编码更加容易,不用折腾 percent encoding。
- 用 POST 写一个接口下单时可能也要考虑幂等,因为前端可能实现“下单按键”有 bug,造成用户一次点击发出 N 个请求。你不能说因为 POST by design 应该是不幂等就不管了。
协议是死的,人是活的。遇到实际的问题时灵活的运用手上的工具满足需求就好。
本文作者:大宽宽
原文链接:https://www.zhihu.com/question/28586791/answer/767316172
版权归作者所有,转载请注明出处