比较
为什么使用 netty 而不是用 jdk 的 nio,因为 netty 支持以下特性:
- 支持常用应用层协议
- 解决传输问题:粘包、半包想象
- 支持流量整形
- 完善的断连、Idle 等异常处理
概念解释
- 阻塞:线程等待去读缓冲区数据(排队打饭)(BIO:Blocking I/O)
- 非阻塞:缓冲区数据填满后呼叫线程(排队叫号)(NIO:Non-blocking I/O)
- 同步:缓冲区数据要线程自己读(菜自己端)
- 异步:系统读好缓冲区数据回调给线程(服务员端菜到包厢)(AIO:Async-blocking I/O)
技术选型和实现
仅推荐 NIO
Netty 仅支持 NIO,首先不建议阻塞 IO,连接数高的情况下,一个 IO 对应一个线程,消耗资源大。Netty 原本支持 AIO 后来也被废弃,因为 Linux 的 AIO 不成熟,相较于 NIO 性能提升不明显。
NIO 不一定由于 BIO,BIO 代码简单,在连接数量少的情况下,BIO 性能不输 NIO,但一般为了扩展考虑所以推荐 NIO
多种 IO 实现
Netty 有多种 IO 实现
| common | Linux | macOS/BSD |
|---|---|---|
| NioEventLoop | EpollEventLoop | KQueueEventLoop |
| NioEventLoopGroup | EpollEventLoopGroup | KQueueEventLoopGroup |
| NioSocketChannel | EpollSocketChannel | KQueueSocketChannel |
| NioServerSocketChannel | EpollServerSocketChannel | KQueueServerSocketChannel |
通用的 NIO 实现在 Linux 实现下也是 Epoll,自己实现是因为对 JDK 中的实现不满意,JDK 的 NIO 默认是水平触发,Netty 支持边缘触发(默认)和水平触发。Netty 实现的垃圾回收更少、性能更好。
Reactor 的三种版本
| BIO | NIO | AIO |
|---|---|---|
| Thread-Per-Connection | Reactor | Proactor |
Reactor 是一种开发模式,模式的核心流程就是:注册事件 -> 扫描事件是否发生 -> 事件发生后做相应处理。
Reactor 具体分为三种模式:
- Reactor 单线程模式
- Reactor 多线程模式
- 主从 Reactor 多线程模式
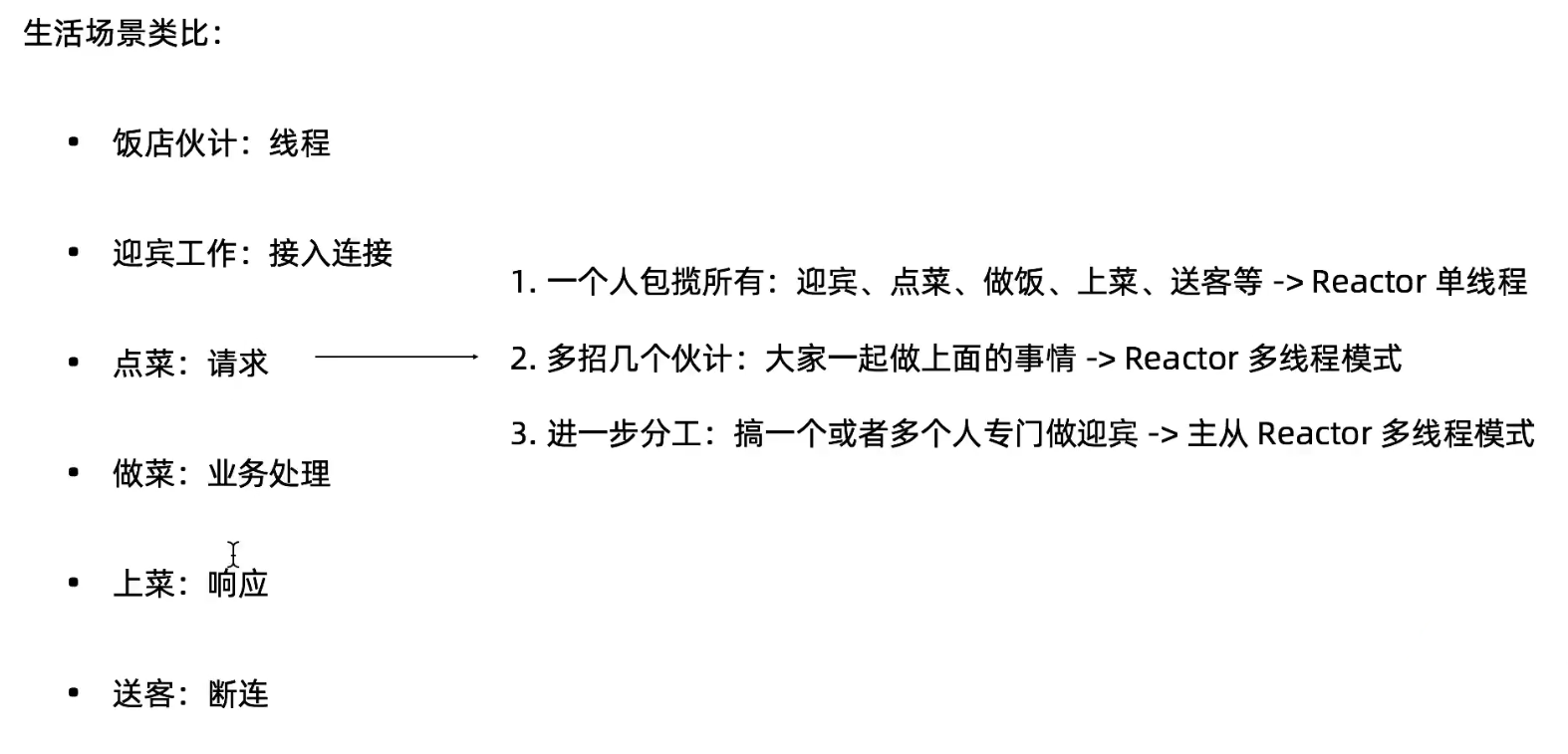
首先我们最熟悉的 BIO 的 Thread-Per-Connection 模式,如下图:
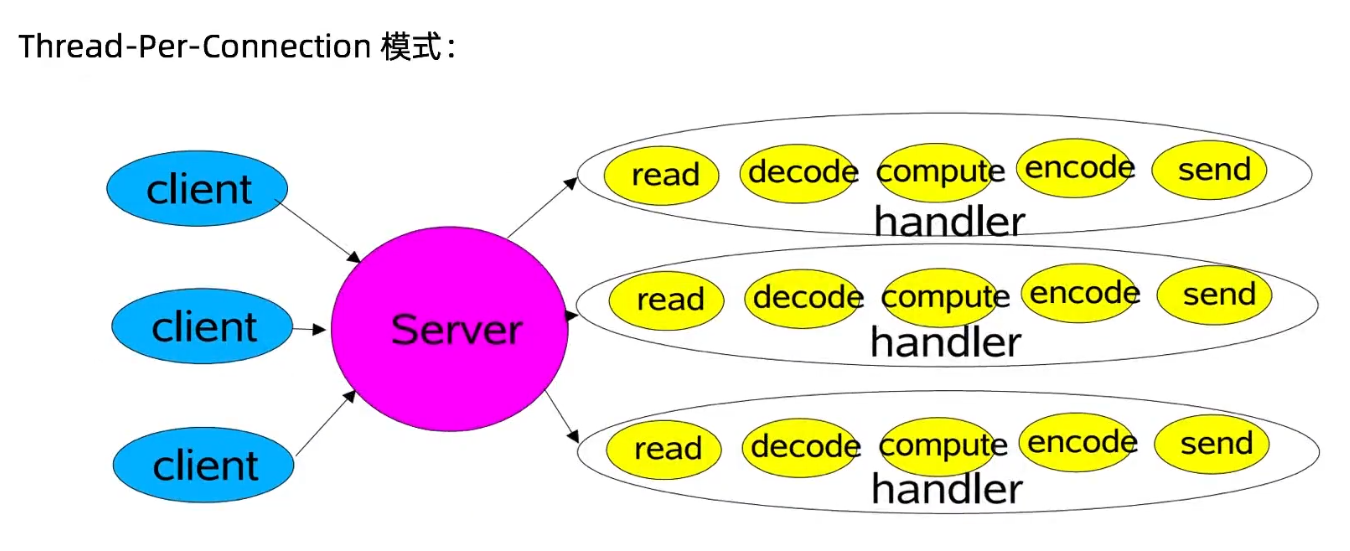
然后看 Reactor 单线程模式:
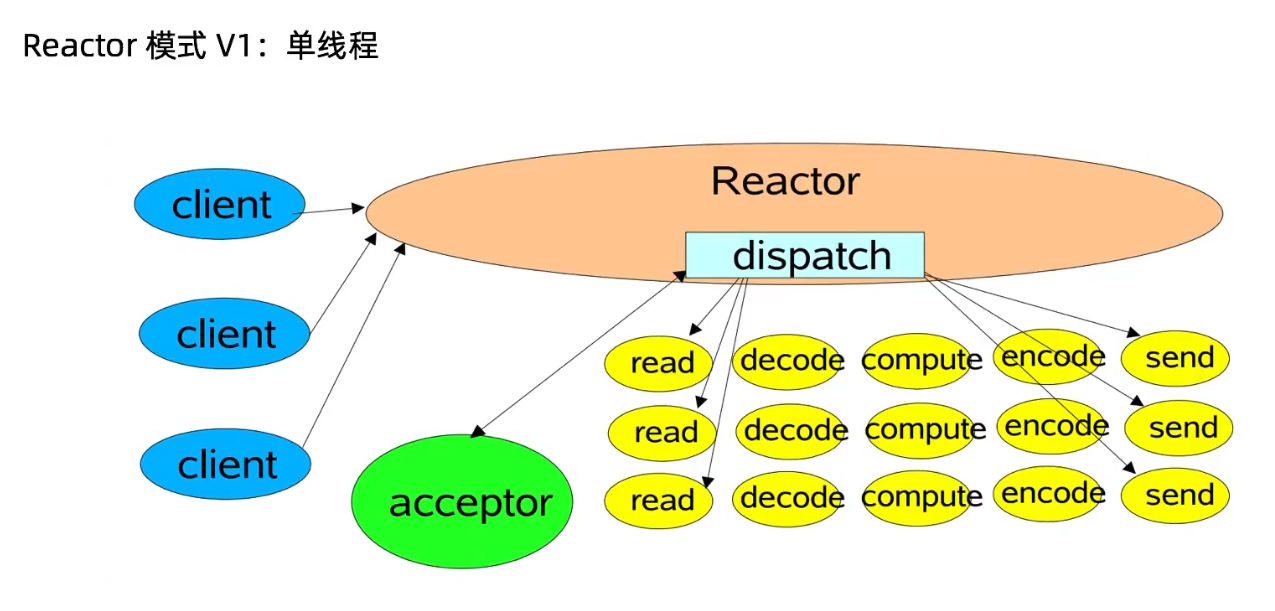
Reactor 多线程模式:
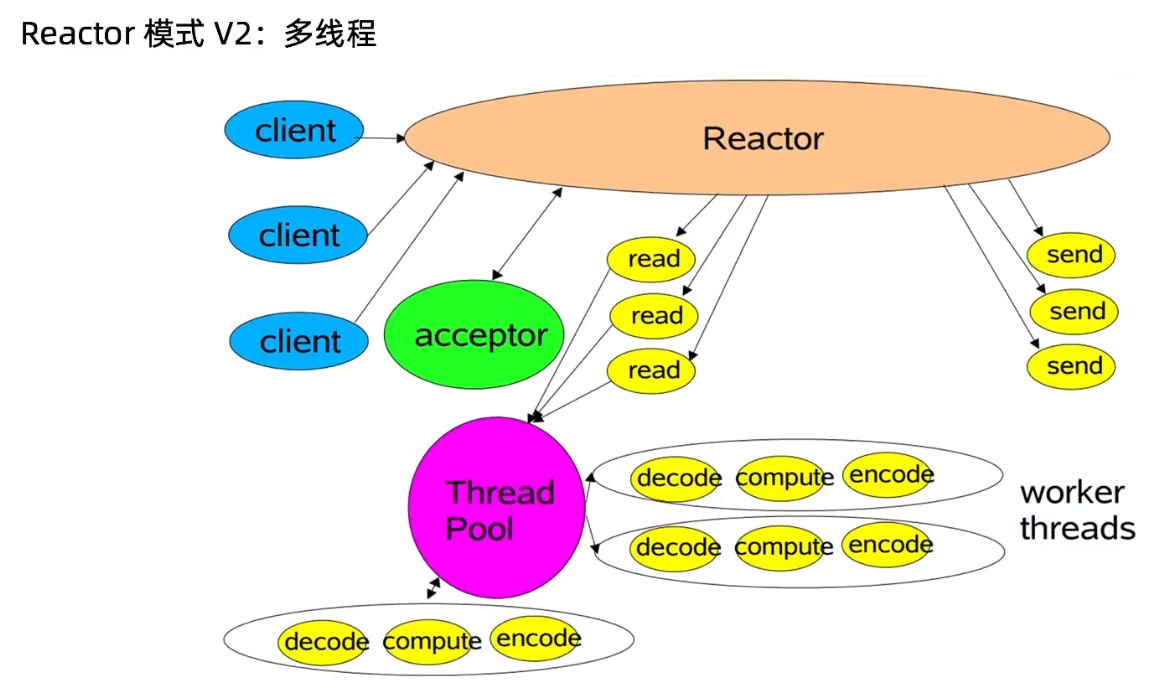
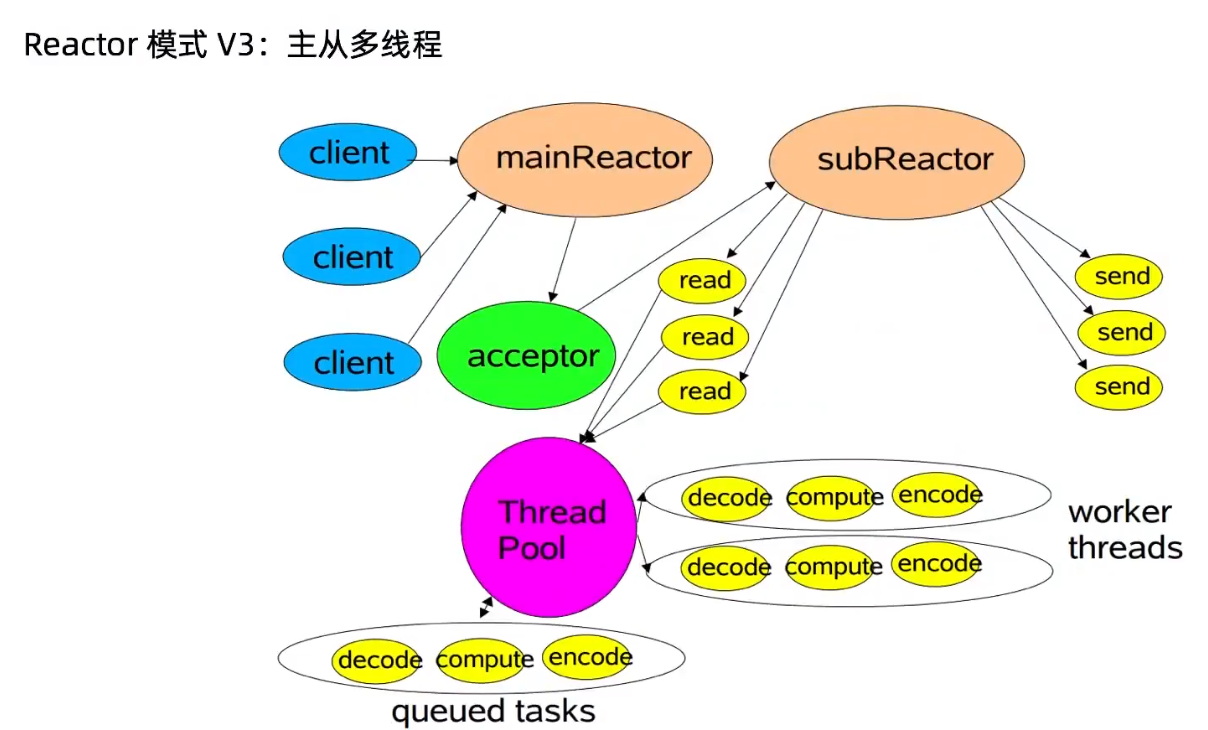
Reactor 主从多线程模式:
粘包半包
在客户端发送数据时,实际是把数据写入到了 TCP 发送缓存里面的。
如果发送的包的大小比 TCP 发送缓存的容量大,那么这个数据包就会被分成多个包,通过 socket 多次发送到服务端,服务端第一次从接受缓存里面获取的数据,实际是整个包的一部分,这时候就产生了半包现象,半包不是说只收到了全包的一半,是说收到了全包的一部分。
如果发送的包的大小比 TCP 发送缓存容量小,并且 TCP 缓存可以存放多个包,那么客户端和服务端的一次通信就可能传递了多个包,这时候服务端从接受缓存就可能一下读取了多个包,这时候就出现了粘包现象。
服务端从接受缓存读取数据后一般都是进行解码操作,也就是会把 byte 流转换了 pojo 对象,如果出现了粘包或者半包现象,则进行转换时候就会出现异常。
出现粘包和半包的原因是 TCP 层不知道上层业务的包的概念,它只是简单的传递流,所以需要上层应用层协议来识别读取的数据是不是一个完整的包。
解决方案:
- 比较常见方案是应用层设计协议时候协议包分为 header 和 body,header 里面记录 body 长度,当服务端从接受缓冲区读取数据后,如果发现数据大小小于包的长度则说明出现了半包,这时候就回退读取缓存的指针,等待下次读事件到来的时候再次测试。如果发现包长度大于了包长度则看长度是包大小整数倍则说明了出现了粘包,则循环读取多个包,否者就是出现了多个整包+半包。
- 多个包之间添加分隔符。
- 包定长,每个包大小固定长度。
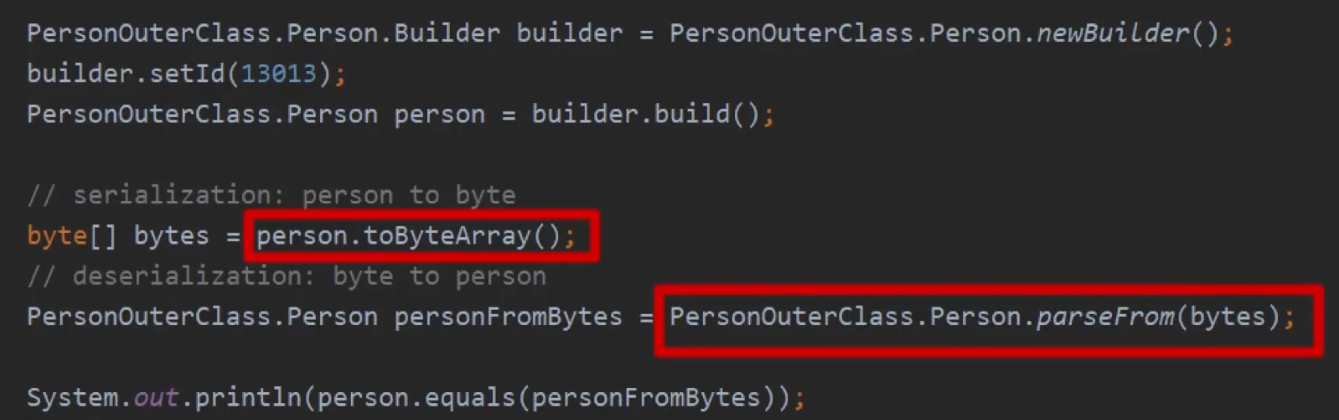
二次编解码
假设我们把解决粘包半包的问题称为一次解码,那除了压缩解压缩外,还需要一次解码,因为一次解码的结果是字节,把字节方便高效的转换成对象称为二次解码,所以对应的编码器是为了将 java 对象转换成字节流方便存储和传输。
是否可以将一次解码和二次解码合二为一?没有分层不够清晰、耦合性高,不容易置换方案
常用的二次编解码方式:
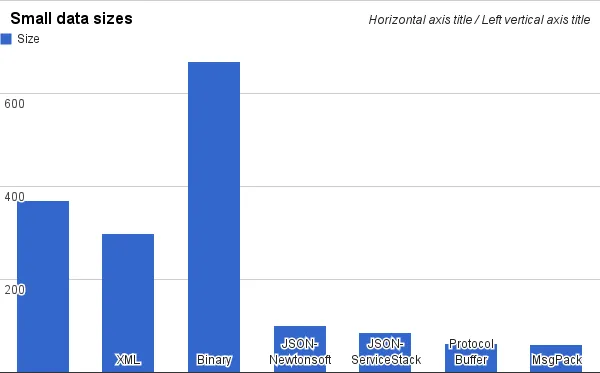
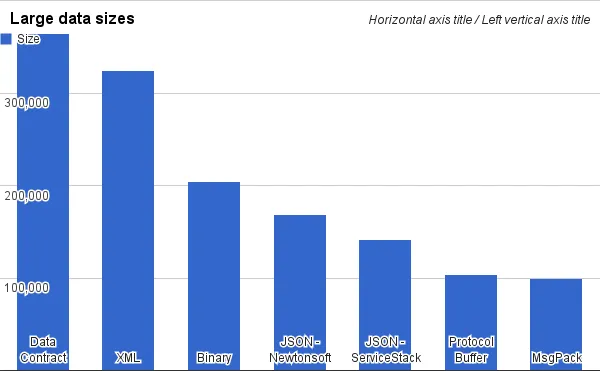
- java 序列化(几乎没人使用,占用空间较大,只有 java 能过够序列化反序列化,无法跨平台)
- xml(空间占用较大)
- json
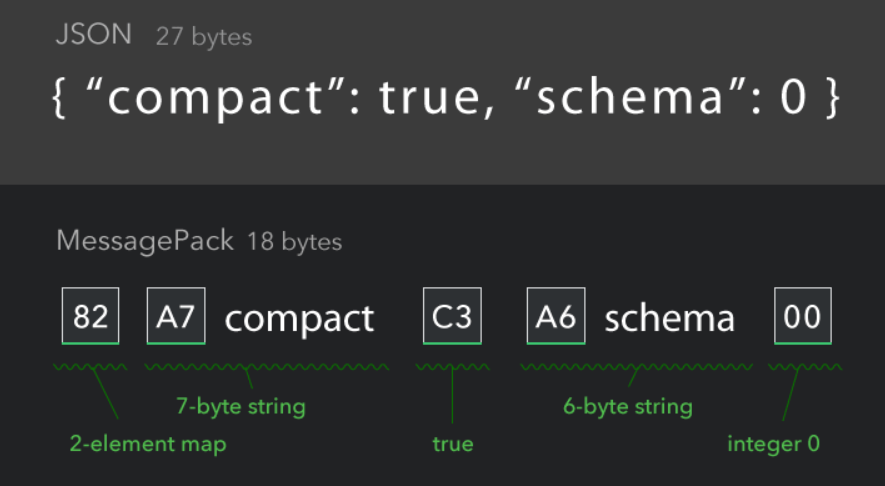
- messagePack(空间比 json 小,可读性弱于 json)
- protobuf(性能非常好,可读性最差)
空间大小比较:
编解码速度比较:
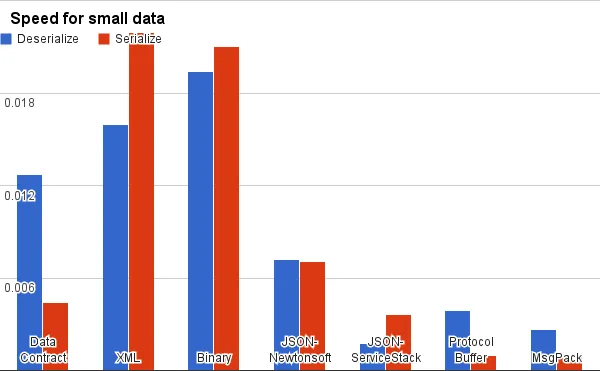
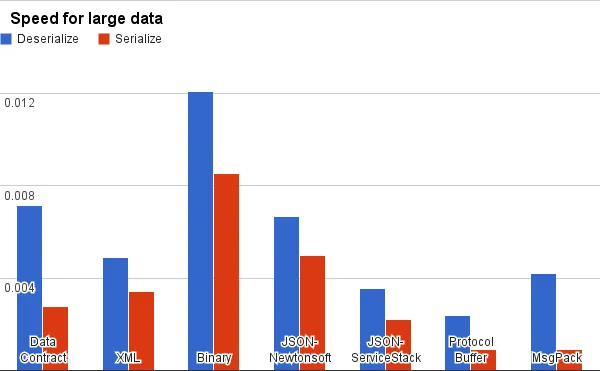
可读性:
跨平台支持:
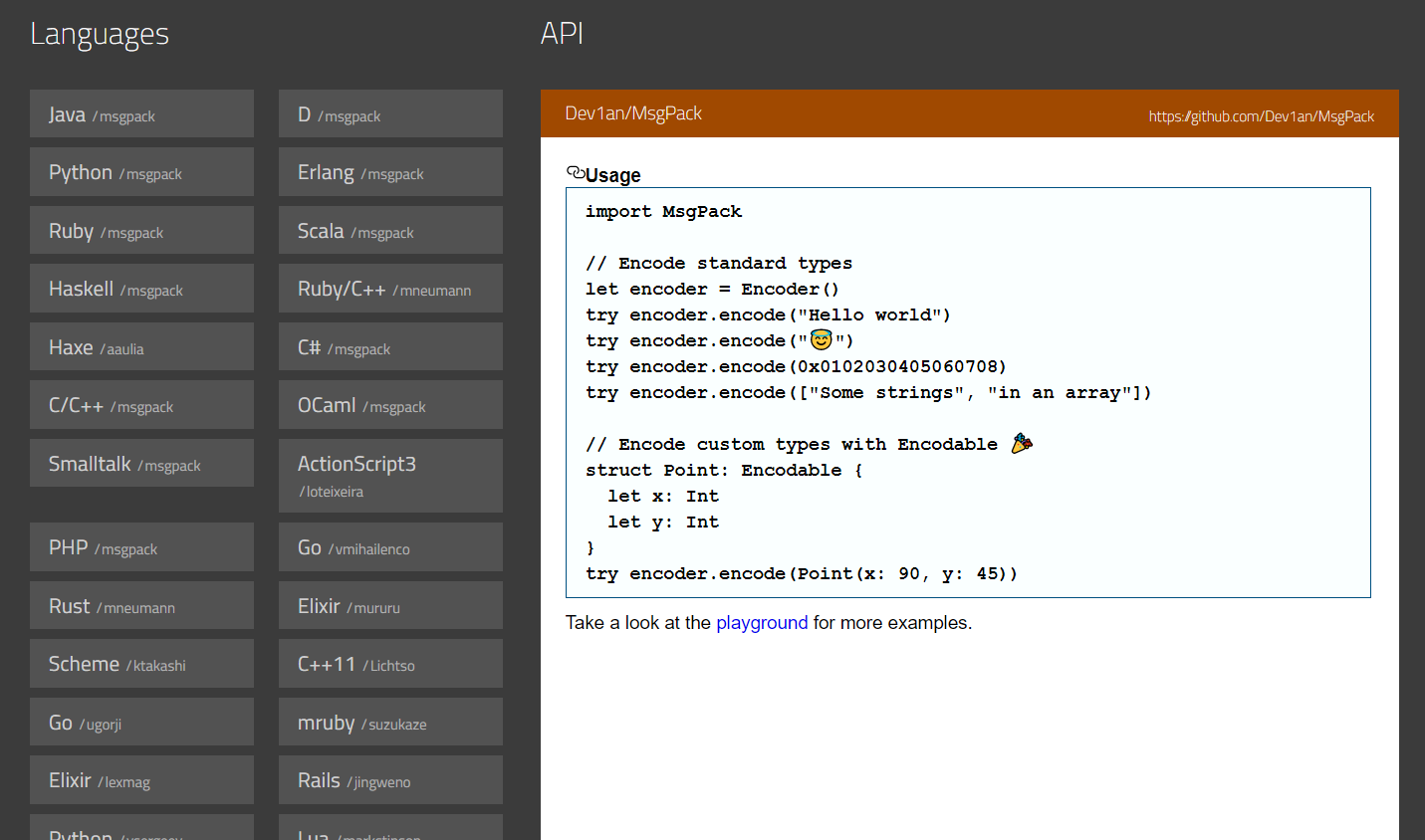
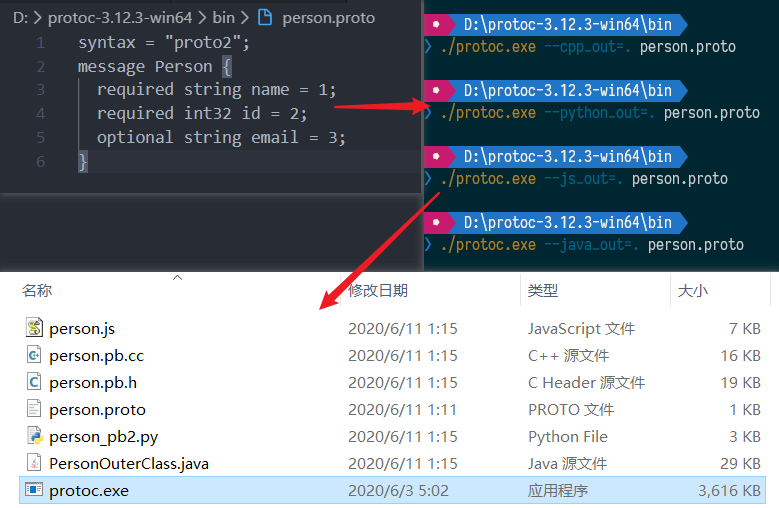
protobuf 简介:它是跨语言的,自带一个编译器,只需用它编译,就可自动生成 java、python、c++等代码
keeplive
需要 keeplive 的场景:
- 对端异常崩溃
- 对端在,但是处理不过来
- 对端在,但是不可达
不做 keeplive 的结果:连接已坏,但是还浪费资源维持,下次直接使用会直接报错。
怎么设计 keeplive?以 TCP keeplive 为例,它的核心参数如下:
1 | # sysctl -a|grep tcp_keepalive |
当启用(默认关闭)keeplive 时,tcp 在持续没有数据 7200 秒(2 小时)后发送 keeplive 请求,当探测没有响应时,按 75 秒的重试频率重发,尝试 9 次后认定连接失效,总耗时 2 小时 11 分钟
虽然 tcp 支持 keeplive 但是往往还是需要应用层自己做 keeplive,为什么不合二为一,tcp 直接就很好的支持呢?
- 原因和上面的二次编解码一样,协议需要分层,传输层只关注连接是否通,应用层关注服务是否可用。类似电话能打通但是没人接,关注点不一样。
- tcp 默认是关闭 keeplive 的,且经过路由等中转设备可能会丢包
- tcp 的 keeplive 时间过长,虽然可以改动,当属于系统参数,改动会影响所有应用。
http 属于应用层协议,”HTTP Keep-Alive”指的是对长连接和短连接的选择,而不是这里的探测机制,不是同一种概念,http 头信息为 “Connection: Keep-Alive”(HTTP/1.1 默认参数,所以不需要带这个 header 了)
Idle(空闲)监测,只是负责诊断,诊断后做出不同的行为。例如一段时间没有数据后,配合 tcp 发送 keepalive 监测,或直接关闭连接。
开启 Idle 监测
1 | /** |