在实施 DDD 的过程中,你最好将那些不怎么使用技术语言的领域专家加进自己的团队。就像你会向他们学习一样,他们也会向你学习。
领域专家并不是一个职位,他可以是精通业务的任何人。他们可能了解更多的关于业务领域的背景知识,他们可能是软件产品的设计者,甚至有可能是销售员。
什么是领域模型?
领域模型是关于某个特定业务领域的软件模型。通常,领域模型通过对象模型来实现,这些对象同时包含了数据和行为,并且表达了准确的业务含义。
领域驱动的好处
- DDD 将领域专家和开发人员聚集到一起,这样所开发的软件能够反映出领域专家的思维模型
- 这并不意味这我们将精力都花在了对“真实世界”的建模上,而是交付最具业务价值的软件。有时在实用和理想之间存在冲突,根据它们的互异程度,在 DDD 中我们将选择实用性。
- 领域专家将和开发人员一起创建一套适用于领域建模的通用语言。通用语言必须在全队范围之内达成一致;所有成员都使用通用语言进行交流,通用语言也是对软件模型的直接反映。
- 通用语言也有助于促使原本存在分歧的领域专家们达成一致意见。此外,通过将领域知识传达给所有的团队成员,包括开发人员,整个团队也将更具凝聚力。我们甚至可以认为,这是每个公司都应该有的对于知识型工作者的起码训练。
- DDD 关注业务战略。
- 它帮助我们定义不同团队之间的组织关系,并在这些关系有可能导致项目失败的时候提供早期预警。
- DDD 的战略设计用于清楚地界分不同的系统和业务关注点,这样可以保护每个业务层面的服务。更进一步,这将指引我们如何实现面向服务架构或者业务驱动架构。
- 通过使用战术设计建模工具,DDD 满足了软件真正的技术需求。
- 这些战术设计工具使开发人员能够按照领域专家的思维模型开发软件。
- 同时,所开发出来的软件是可测试的,能够尽量避免错误,能执行服务层面协议(Service-LevelAgreement,SLA),具有很好的伸缩性,并且允许分布式计算。
- DDD 的最佳实践同时包含了高层的架构性实践和底层设计实践,关注业务规则和数据不变性,并且可以对业务规则起到保护作用。
处理领域复杂性
在使用 DDD 时,我们首先希望将它应用在最重要的业务场景下。对于那些可以轻易替换的软件来说,你是不会有所投入的。相反,值得你投入的是那些重要的、复杂的东西,因为这些东西将为你带来可观的回报。正因如此,我们将这样的模型命名为核心域(Core Domain,2),而那些相对次要的称为支撑子域(Supporting Subdomain,2)。
DDD 的作用是简化,而不是复杂化
不同的业务领域对于复杂的定义是不一样的。另外,不同的公司所面临的挑战不一样;成熟度不一样;软件开发能力也不一样。因此,与其去定义什么是复杂的,还不如定义什么是重要的。这时,你的团队和管理层应该做出决定:你们开发的软件系统是否值得做出 DDD 投入。
DDD 计分卡
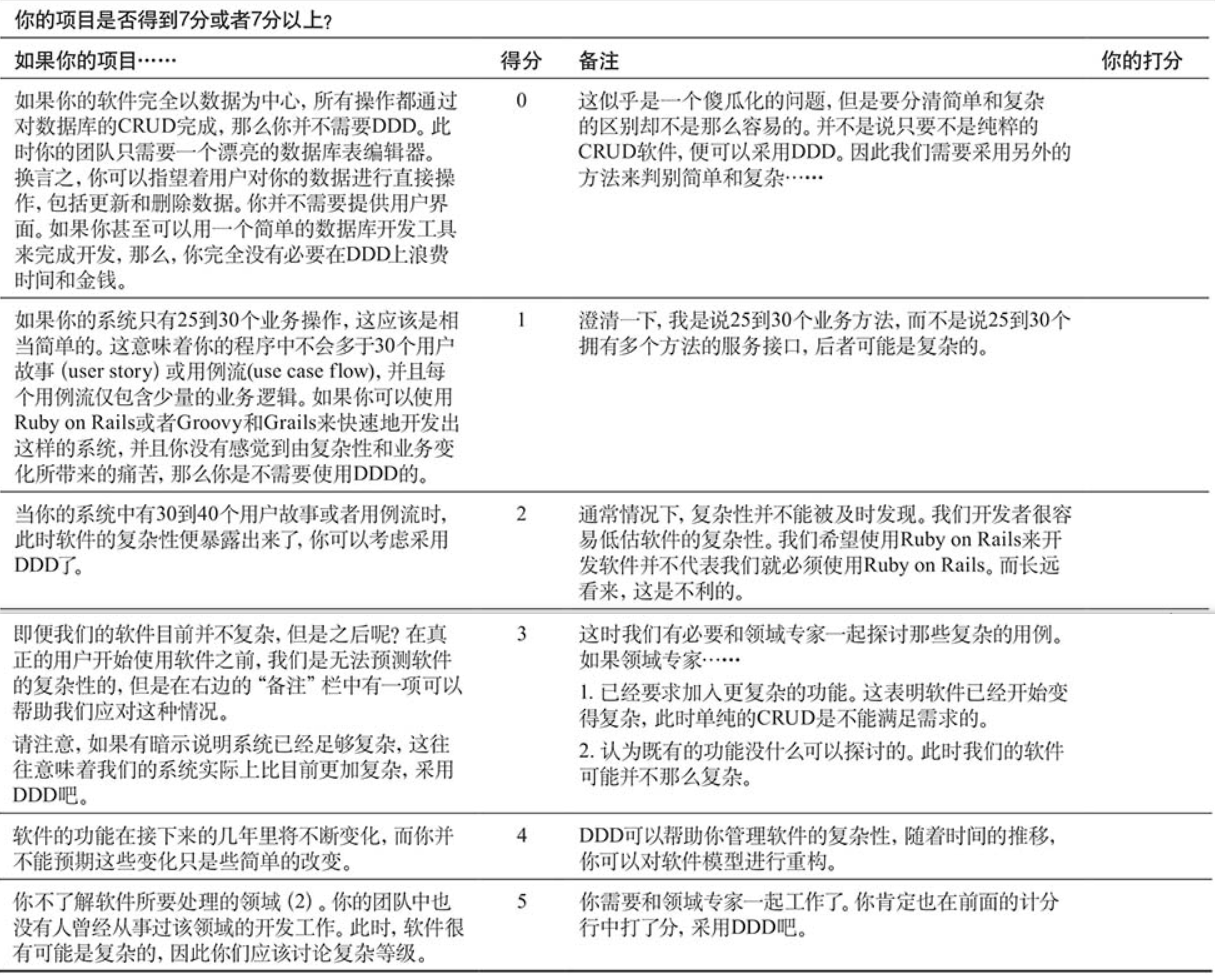
一旦我们做出了重要的架构决策,并且已经在该架构下进行了深入地开发,通常我们也被绑定在这个架构下了,所以在决定时一定要慎重。
贫血模型
你所说的领域对象根本就不是领域对象,而只是将关系型数据库中的模型映射到了对象上而已。这样的领域对象更像是活动记录(Active Record),此时你可以对架构做个简化,然后使用事务脚本(Transaction Script)进行开发。
如果说贫血领域对象是由设计不当造成的,为什么还有如此多的人认为他们的领域对象是健康的呢?其中一个原因是:贫血领域对象反映了一种自然的过程式的编程风格,但我并不认为这是首要原因。软件业中有很多开发者都是学着示例代码做开发的,这并不是什么坏事,只要示例代码本身是好的。然而,通常情况是,示例代码只是用尽可能简单的方式来展示某个特定的概念或者 API 特性,而并不强调要遵循多好的设计原则。
示例一
阅读一个贫血领域对象的示例代码,比如应用服务中的事务脚本

以上代码完成了什么功能呢?事实上,以上代码的功能是相当强大的。不管一个 Customer 是新建的还是先前存在的;不管是 Customer 的名字变了还是他搬进了新家;不管是他的家用电话号码变了还是他有了新的移动电话;也不管他是改用 Gmail 还是有了新的 E-mail 地址,这段代码都会保存这个 Customer。
情况真是这样的吗?其实,我们并不知道 saveCustomer() 方法的业务场景。你不相信?那请看看该方法的下一个版本:

我们能说这是好的代码吗?我们如何测试这段代码以保证在错误的业务场景下该段代码不应该保存一个 Customer 呢?都不用讨论过多的细节我们便知道,在很多情况下该方法是不能正常工作的。
你可能会查看很多客户代码,然后比较代码历史,找出 saveCustomer()的来龙去脉。你会发现,没有人能够解释这个方法为什么会成为现在这个样子,也没有人知道究竟有多少客户代码在正确地使用 saveCustomer()方法。
上面的 saveCustomer()至少存在三大问题:
- saveCustomer()业务意图不明确。
- 方法的实现本身增加了潜在的复杂性。
- Customer 领域对象根本就不是对象,而只一个数据持有器(data holder)。
我们将这种情况称为由贫血症导致的失忆症,在实际项目中,这种症状发生得太多了。
我们将修改 Customer,使其能够反映出它应该支持的业务操作:

对领域模型的修改也将导致对应用层的修改。每一个应用层的方法都对应着一个单一的用例流:

在使用 DDD 时,我们应该对照着模型的修改相应地修改应用层。同时,这也意味着用户界面所反映的用户操作也变得更加狭窄。但是无论如何,这个特定的应用层方法不再要求我们在用户姓名参数之后跟上 10 个 null 了。
因此,我们使用通用语言来捕捉特定核心业务领域中的概念和术语,它是一种团队模式。软件模型包含名词、形容词、动词和一些富有含义的语句等,团队成员便通过这些语言进行交流。软件实现和测试中也使用和团队语言一样的通用语言。
示例二
我们需要将一个待定项(Backlog Item)提交到冲刺(Sprint)中去。
通常的做法,使用属性访问的方式:

客户代码如下:

第一个例子采用的是以数据为中心的方式,此时客户代码必须知道如何正确地将一个待定项提交到冲刺中。这样的模型是不能称为领域模型的。如果客户代码错误地修改了 sprintId,而没有修改 status 会发生什么呢?或者,如果在将来有另外一个属性需要设值时又该怎么办?我们需要认真分析客户代码来完成从客户数据到 BacklogItem 属性的映射。
这种方式同时也暴露了 BacklogItem 的数据结构,并且将关注点集中在数据属性上,而不是对象行为。你可能会反驳道:“setSprintId()和 setStatus()就是行为啊。”问题在于,这里的“行为”没有真正的业务价值,它并没有表明领域模型中的概念——此处即“将待定项提交到冲刺中”。开发者在开发客户代码时,他并不清楚到底需要为 BacklogItem 的哪些属性设值,而这样的属性有可能存在很多,因为这是一个以数据为中心的模型。
如果需求进行增加:允许将每一个待定项提交到冲刺中。只有在一个待定项位于发布计划(Release)中时才能进行提交。如果一个待定项已经提交到了另外一个冲刺中,那么需要先将其回收 。提交完成时,通知相关客户方。
领域驱动的写法:

客户代码如下:

我们并不需要关心如何发布回收事件,因为 uncommitFrom()方法会为我们处理这些。而 commitTo()方法甚至都不知道发布回收事件这码事,它只需要知道,在将待定项提交给一个新的冲刺时,必须先将该待定项从它当前所在的冲刺中回收。另外,commitTo()的领域行为还包括:在提交待定项完毕后,以事件形式通知相关客户方。如果不是这个富含行为的 BacklogItem,我们得在客户代码中发布领域事件,这显然是一种领域逻辑的泄漏。