- Prometheus 采用拉取数据的方式
- 时序数据库
指标
由于指标和度量对监控框架至关重要,通常记录一段时间内的数据点。这些数据点称为观察点(observation),观察点通常包括值、时间戳,有时也涵盖描述观察点的一系列属性(如源或标签)。
通常以固定的时间间隔收集数据,该时间间隔被称为颗粒度(granularity)或分辨率(resolution),取值可以从 1 秒到 5 分钟,甚至到 60 分钟或更长。正确地选择指标的颗粒度至关重要,若选择得太粗糙,则很容易错过某些细节。通常以固定的时间间隔收集数据,该时间间隔被称为颗粒度(granularity)或分辨率(resolution),取值可以从 1 秒到 5 分钟,甚至到 60 分钟或更长。正确地选择指标的颗粒度至关重要,若选择得太粗糙,则很容易错过某些细节。
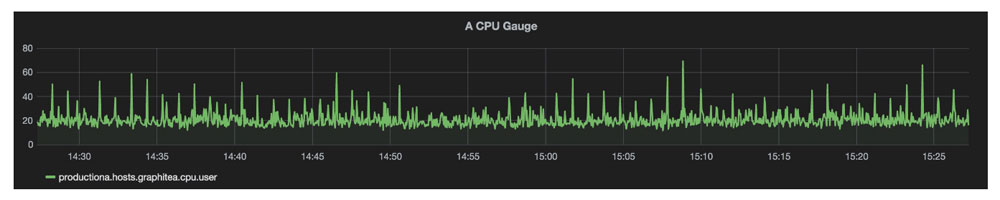
测量型
常见的监控指标如 CPU、内存和磁盘使用率等都属于这个类型。
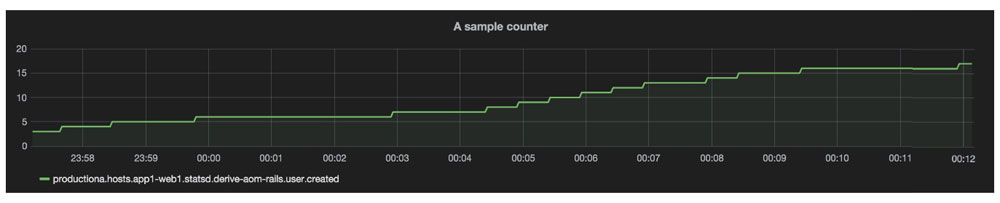
计数型
这种类型是随着时间增加而不会减少的数字。
直方图
对观察点进行采样的指标类型

指标摘要
计数、求和、平均值、中间数、百分位数、标准差、变化率
指标聚合
除了指标摘要外,你可能经常希望能看到来自多个源的指标的聚合视图。就是在一张图上显示多个指标,这有助于你识别环境的发展趋势。
Prometheus 简介
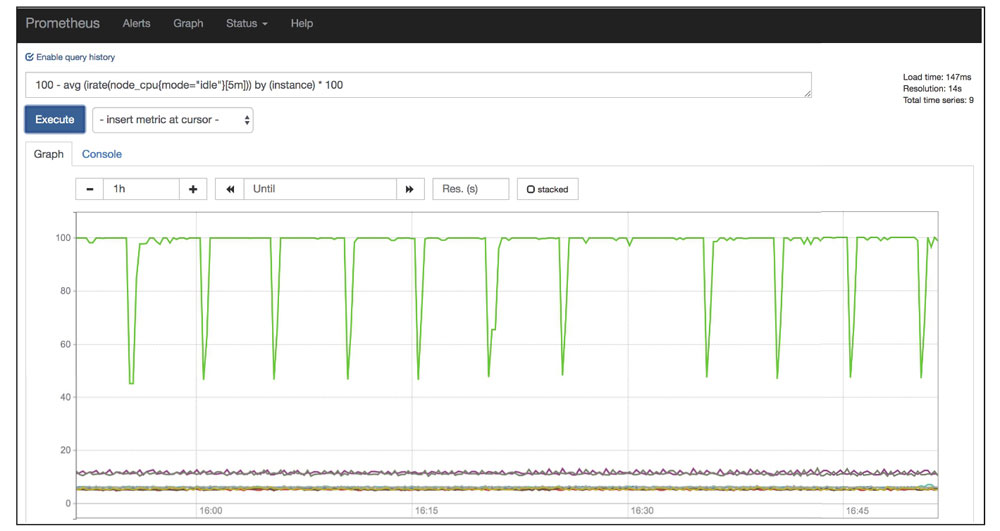
Prometheus 专注于现在正在发生的事情,而不是追踪数周或数月前的数据。它基于这样一个前提,即大多数监控查询和警报都是从最近的(通常是一天内的)数据中生成的。
Prometheus 称其可以抓取的指标来源为端点(endpoint)。
生成的时间序列数据将被收集并存储在 Prometheus 服务器本地,也可以设置从服务器发送数据到外部存储器或其他时间序列数据库。
服务器还可以查询和聚合时间序列数据,并创建规则来记录常用的查询和聚合。
Prometheus 服务器没有内置警报工具,而是将警报从 Prometheus 服务器推送到名为 Alertmanager(警报管理器)的单独服务器。
Prometheus 服务器还提供了一套内置查询语言 PromQL、一个表达式浏览器
时间序列由名称和标签标识(键/值)(尽管从技术上讲,名称本身也是名为_name_的标签)进行分组。

可以看到 Prometheus 如何将时间序列表示为符号(notation),例如,带有标签的 total_website_visits 时间序列可能如下所示

首先是时间序列名称,后面跟着一组键/值对标签。通常所有时间序列都有一个 instance 标签(标识源主机或应用程序)以及一个 job 标签(包含抓取特定时间序列的作业名称)。
Prometheus 专为短期监控和警报需求而设计。默认情况下,它在其数据库中保留 15 天的时间序列数据。如果要保留更长时间的数据,则建议将所需数据发送到远程的第三方平台。
关于安全有以下两个假设:不受信任的用户将能够访问 Prometheus 服务器的 HTTP API,从而访问数据库中的所有数据。只有受信任的用户才能访问 Prometheus 命令行、配置文件、规则文件和运行时配置。